For security issue we decided to enable LDAP in presto, to deploy presto into kubernetes cluster we build presto image ourselves which include kerberos authentication and LDAP configurations.
As you see the image structure, configurations under catalog/etc/hive are very important, please pay attention.
krb5.conf and xxx.keytabare used to connect to kerberos
password-authenticator.properties and ldap_server.pem under etc, hive.properties and hive-security.json under catalog are used to connect to LDAP.
For every project we generate pipeline scripts by JHipster like this:
ci contains docker related scripts, cd contains kubernetes related scripts.
We configured Jenkins to scan projects from git automatically which followed naming rule, if any changes on git, Jenkins will pull the code and start building.
There are 3 ways to expose your service: NodePort, LoadBalancer, Ingress, next I will introduce about how to use ingress.
1.Deploy ingress controller
You need deploy ingress controller at first which will start nginx pods, then nginx will bind domains and listen to the requests.
I built a common ingress chart for different service, I only need change values-<service>.yaml and deploy script if any changes.
Another key point is that you must be clear about ingress-class, different service use different ingress-class, it will be quite messy if you mistake them.
Next we need configure service ingress which will append nginx server configuration dynamically.
I also built a service chart which include environment configurations, Jenkins & Helm will use different values-<env>.yaml when execute pipeline deployment.
There’s two kinds of probe: readinessProbe, livenessProbe in kubernetes used to detect if your service is healthy.
We encountered a problem when configured readinessProbe, there’s a property named initialDelaySeconds which indicate kubernetes will start health check after specific second, we used the default value 60 which means kubernetes will check health after 60 seconds.
As we deployed over 20 StatefulSet pods and these pods joined as a cluster which cost over 60 seconds, kubernetes can’t ping service successfully so that kubernetes restart these pods, thees pods restart in loop all the time.
After we increased the initialDelaySeconds to 120, everything goes fine.
If you deploy pod by setting “kind: Deployment“, you will lost your data when the pod restart or being deleted.
It’s not acceptable when we want to deploy storage system like Redis, Elasticsearch, in this case we need use StatefulSet.
For the concrete explanation please refer to the official documentation, StatefulSet use PVC(Persistent Volume Claim) as storage, and it will exist all the time no matter what happened to the pod.
You must specify PVC in StatefulSet’s yaml file like this:
When we deploy a API in kubernets we must define replication number for the pod, but as we know there will be high traffic during peak time and we usually can’t estimate service capacity exactly at first time, in this case we must scale our service like creating more pods to share online traffic to avoid service crash down.
We usually scale service manually before using kubernetes, append more nodes during peak time and destroy nodes when the traffic became smooth.
In kubernetes there’s a kind of feature called HPA(Horizontal Pod Autoscaler) which could help your scale service automatically. You could specify minimum and maximum replica number in yaml file, HPA will monitor pod’s CPU and Memory by collecting pod’s metric, if HPA found your pod’s metric is over the threshold number which you defined in yaml file, it will create more pods automatically and join the service cluster to load the traffic.
As you know kubernetes is the most popular container orchestration tool which helps us deploy/manage/scale container and service more easily.
We deploy kubernetes cluster by kuberspray which could help us build production ready cluster very fast and provide many convenient tools. Before start deploying you must configure SSH key between nodes.
It’s boring and complicated to manage bigdata platforms, there are so many softwares need to be installed and coordinated to make them work well together, so I tried ambari to manage them.
1.run centos7 container
docker run -dit --name centos7 --privileged --publish 8080:8080 centos:7 /usr/sbin/init
The above steps are configured on single server, if you wanna build cluster with several servers, you also need configure ssh key(please google for specific steps, it’s simple) and start ambari-agent on slave servers.
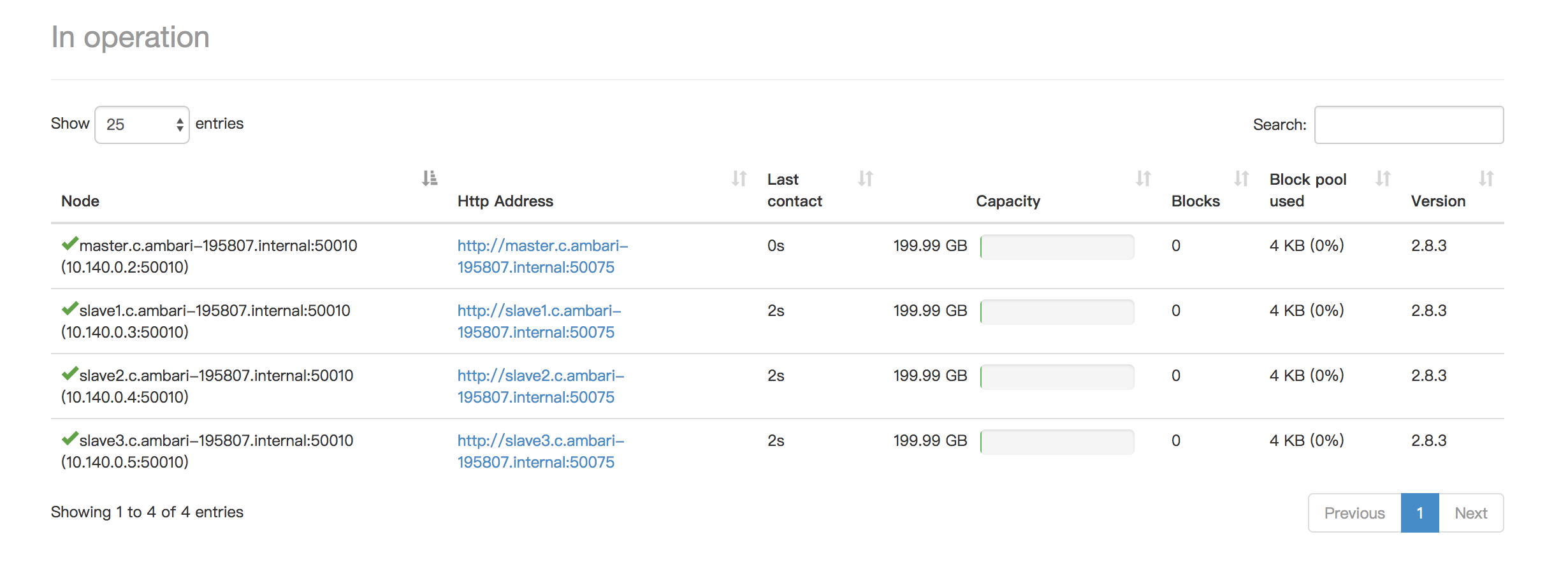
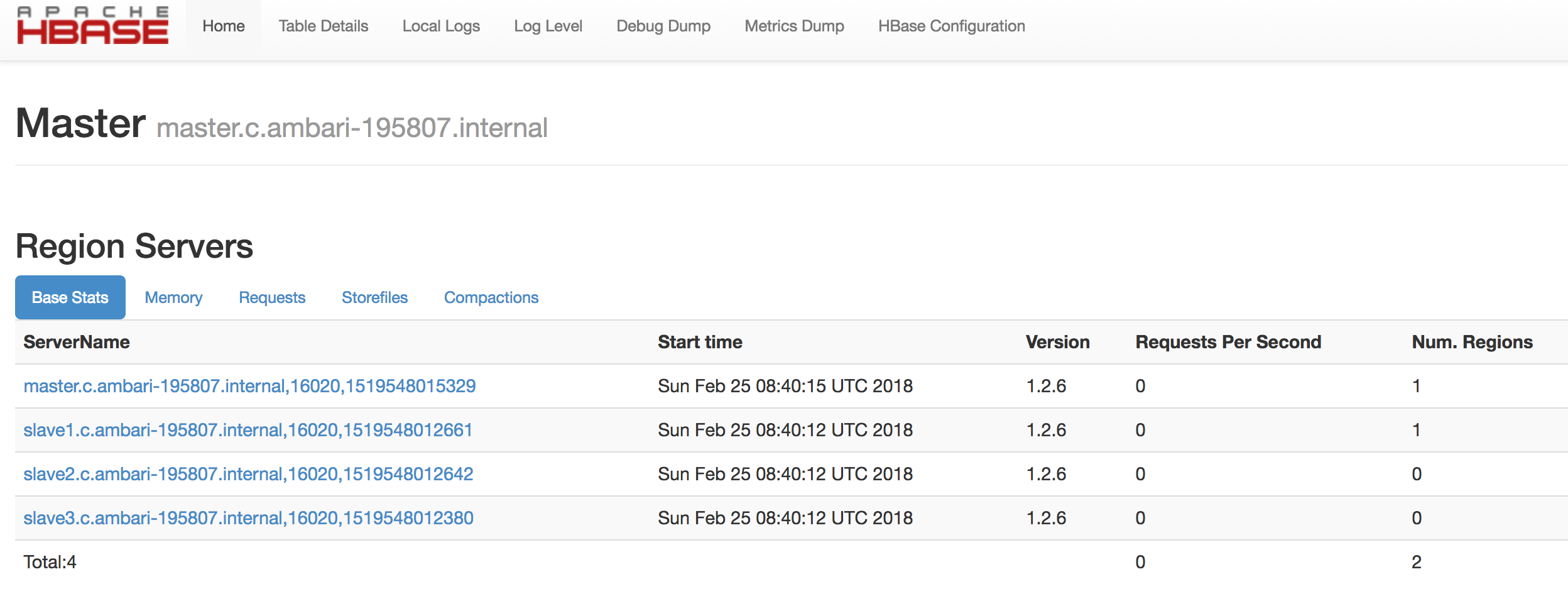
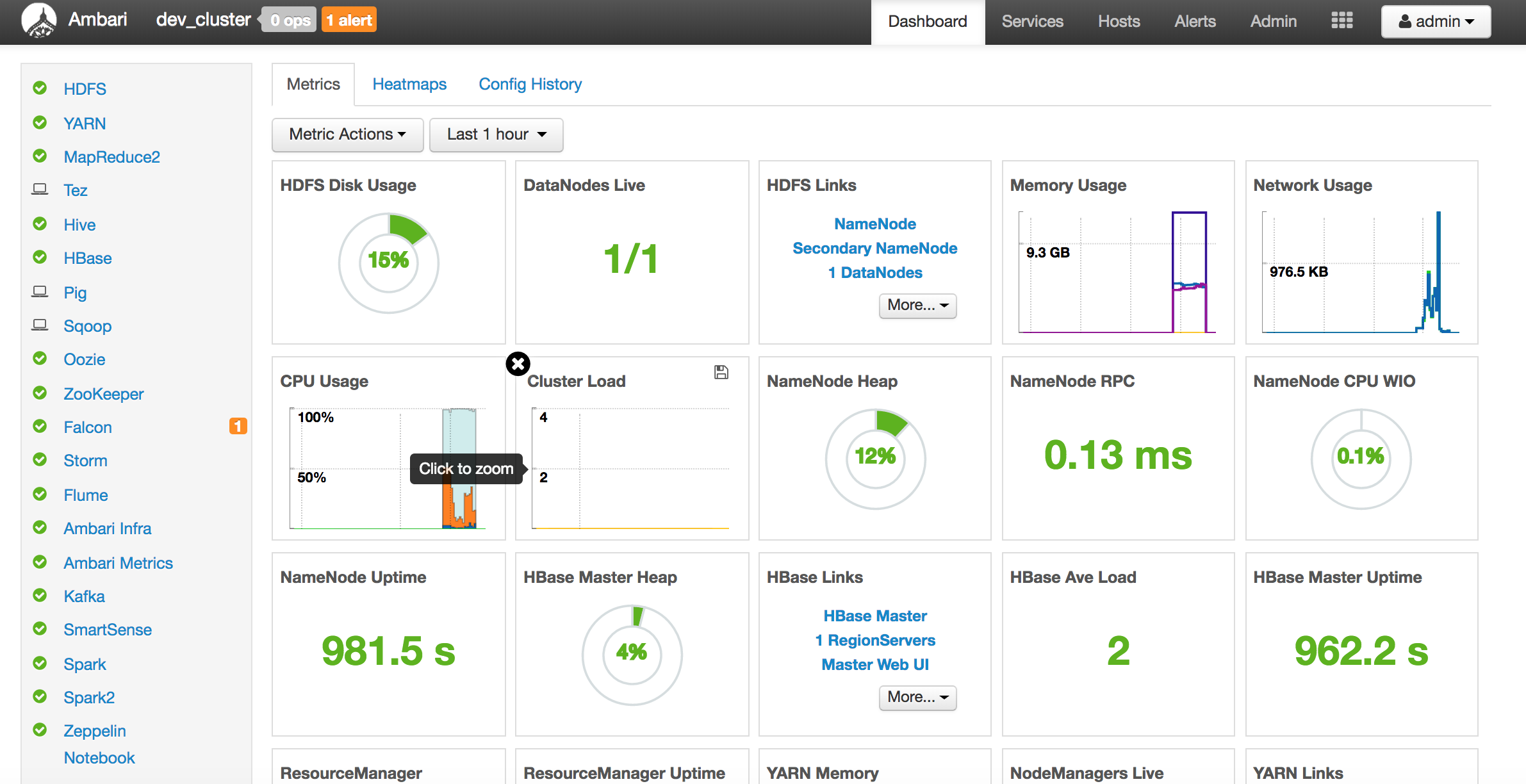
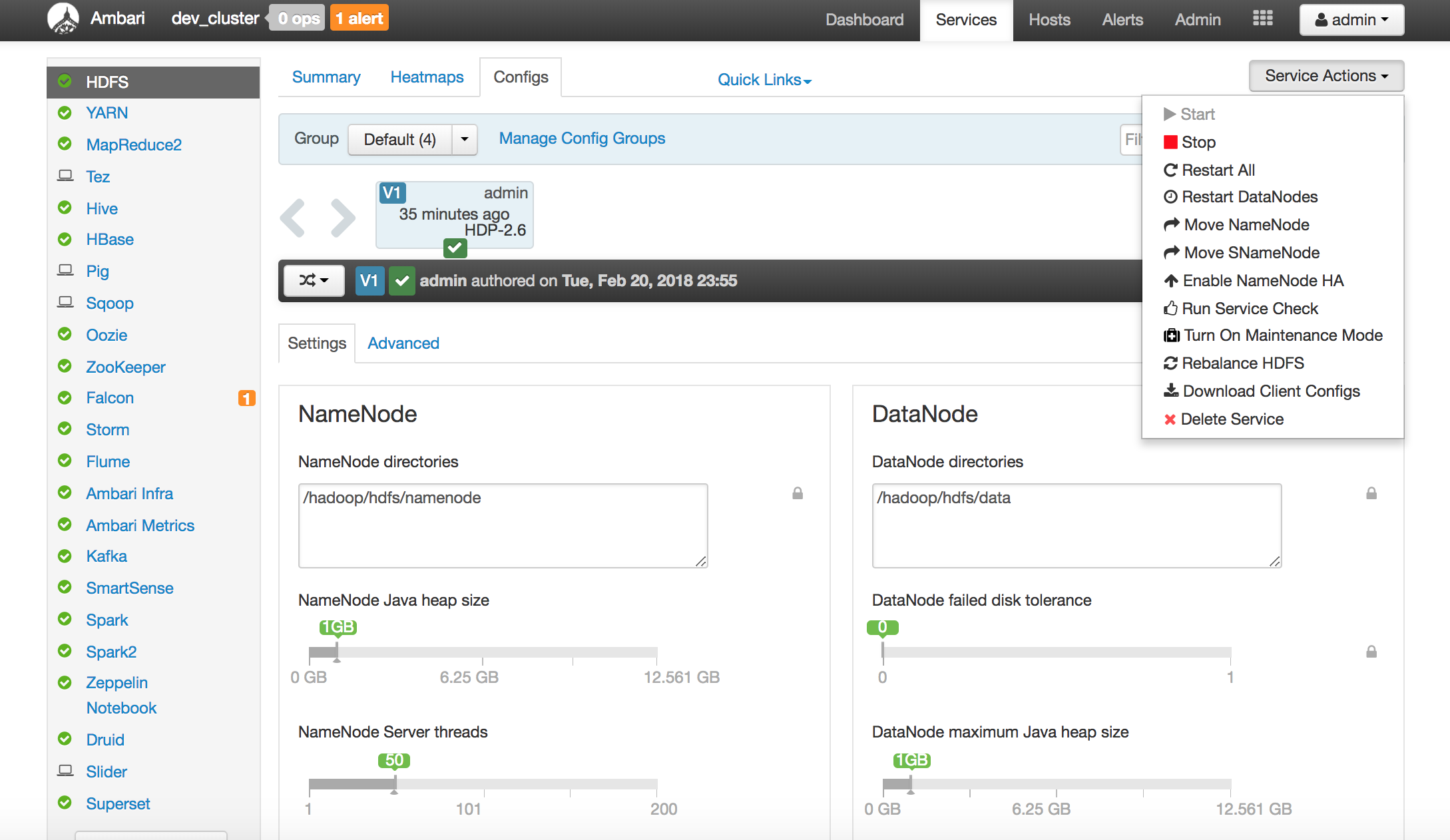
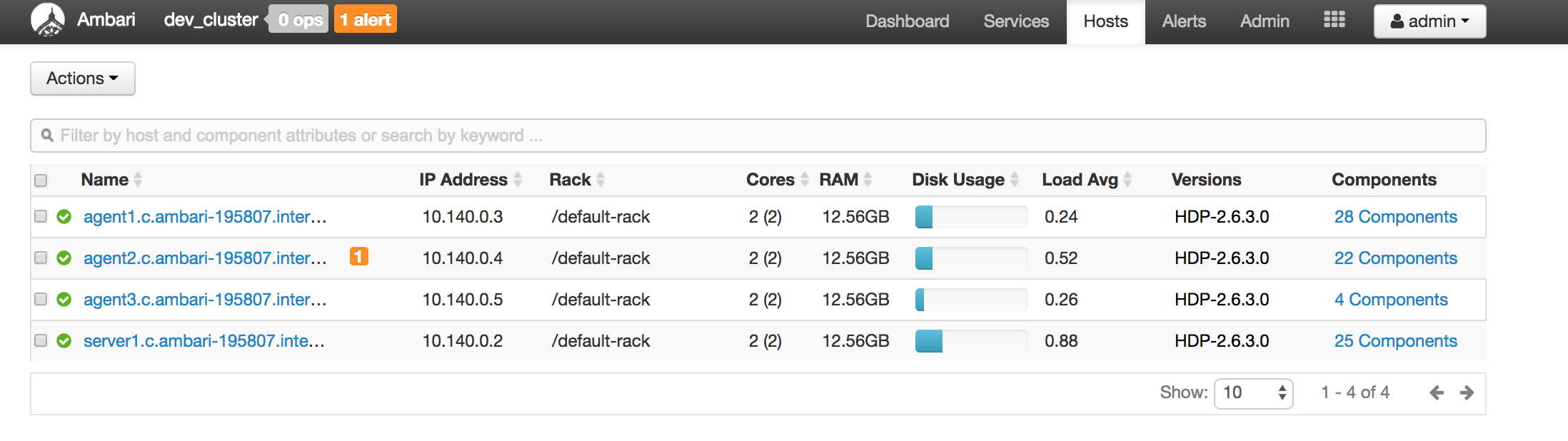
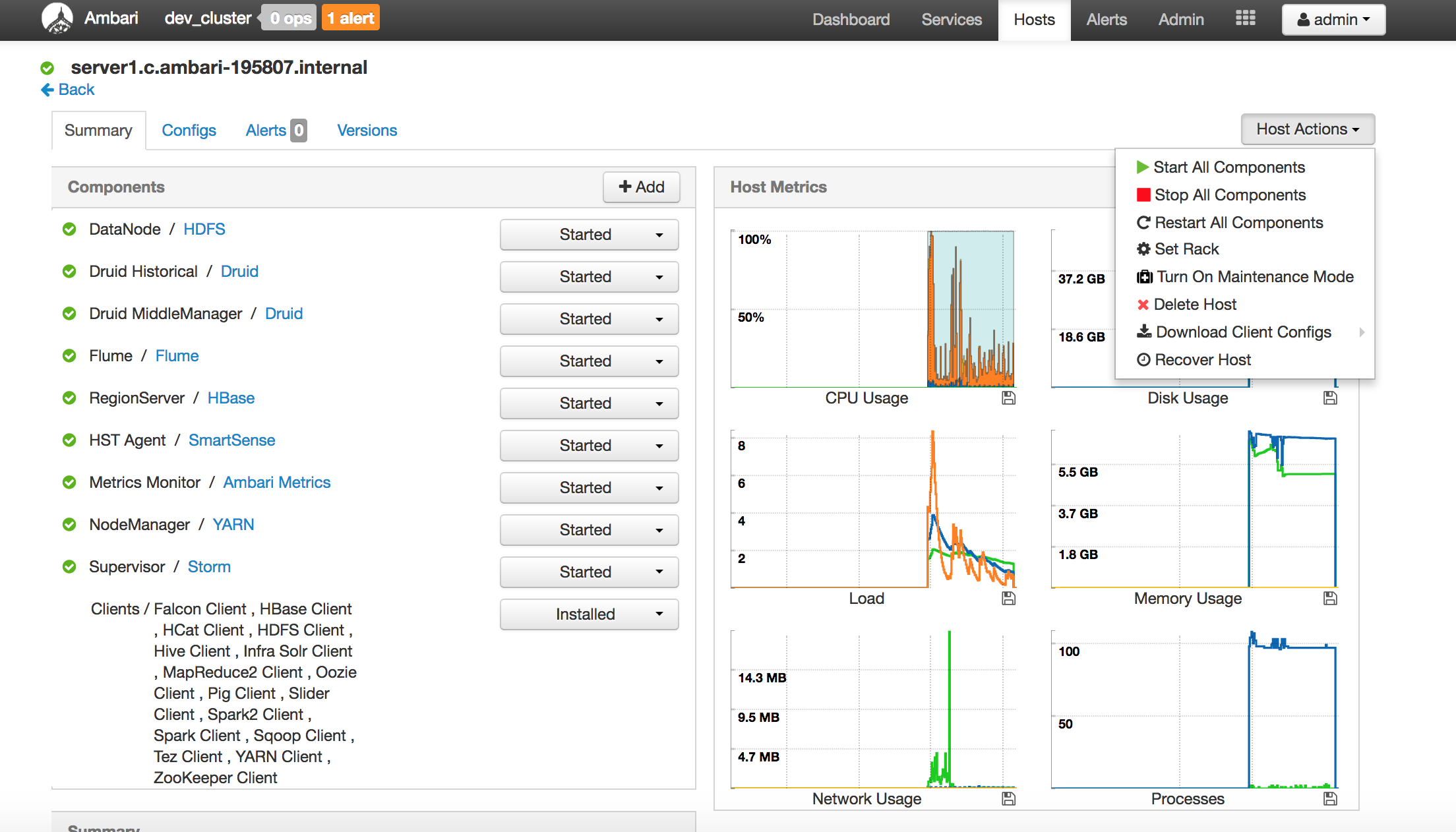
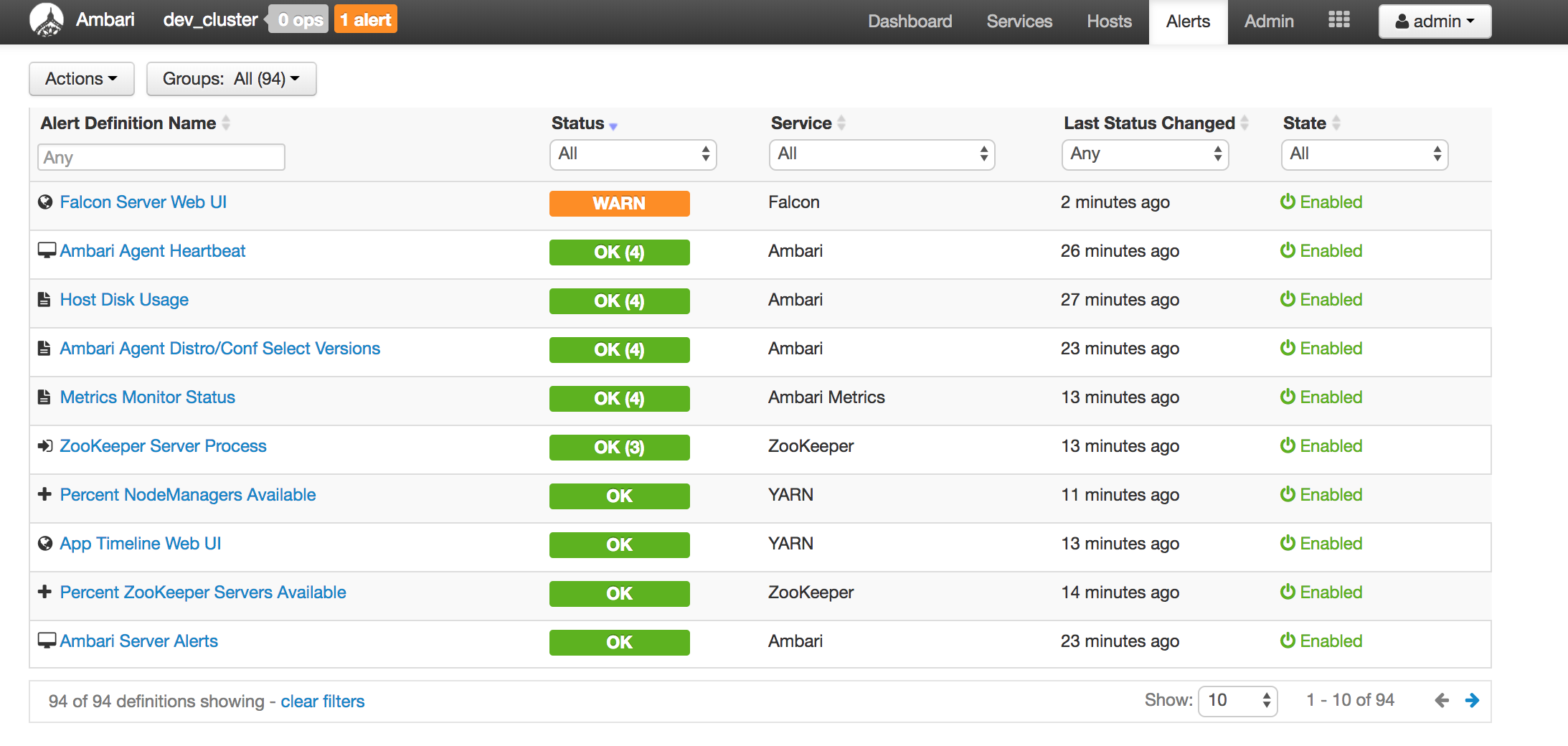
Below are screenshots of a mini cluster which was built by 4 servers:












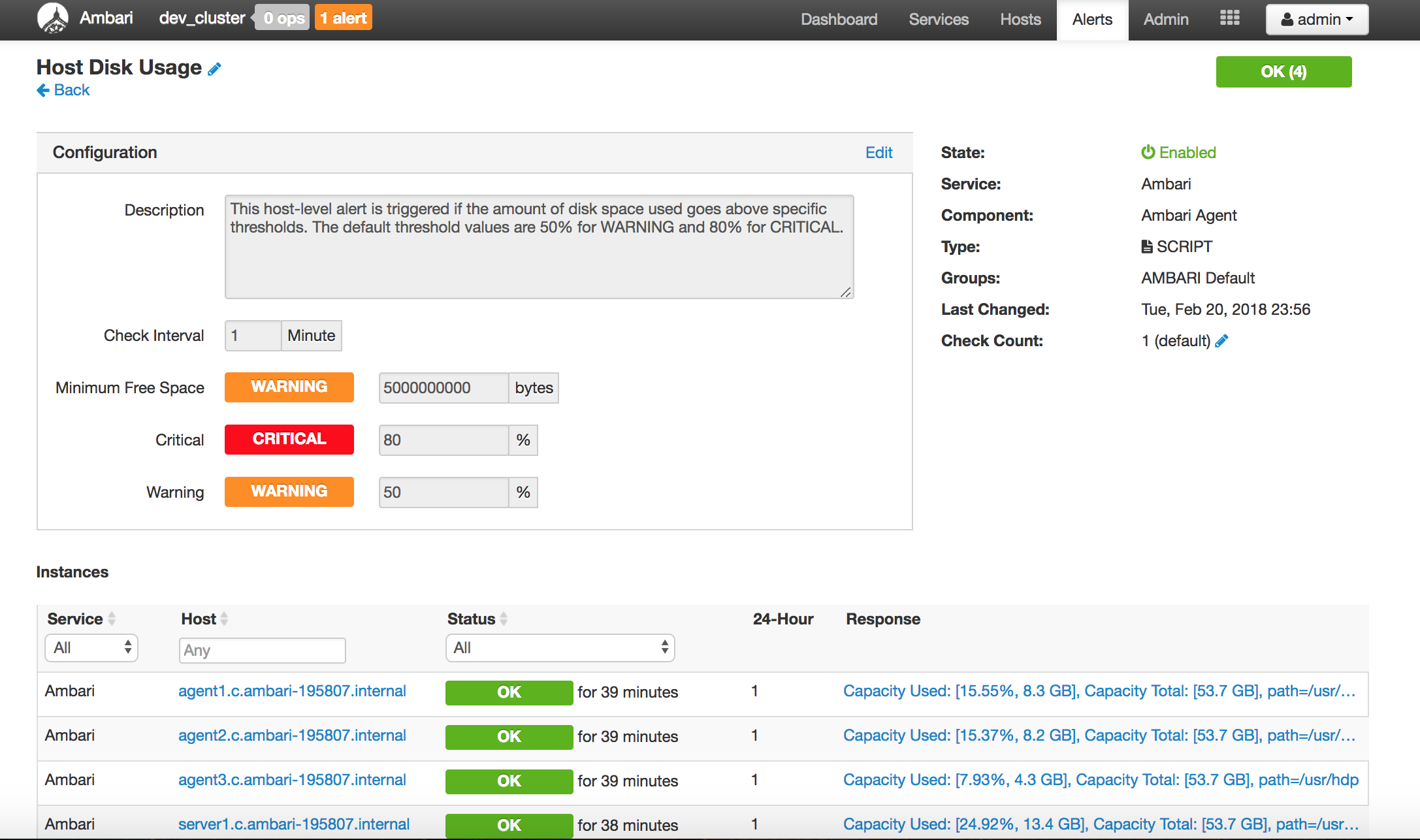

Reply