From hive2 Hive-on-MR is not recommended, you could see the warning information when running hive cli
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
So I installed Tez to replace MR to run jobs, below are installation steps.
1.install Tez
1.1.down Tez and unpackage
wget http://ftp.jaist.ac.jp/pub/apache/tez/0.9.0/apache-tez-0.9.0-src.tar.gz
tar -zvxf apache-tez-0.9.0-src.tar.gz && cd apache-tez-0.9.0-src
1.2.compile and build Tez jar, you need install protobuf/maven before compiling
mvn clean package -DskipTests=true -Dmaven.javadoc.skip=true
1.3.upload Tez to hdfs
hadoop fs -mkdir /apps
hadoop fs -copyFromLocal tez-dist/target/tez-0.9.0.tar.gz /apps/
1.4.create tez-site.xml under hadoop conf directory
cat <<'EOF' > $HADOOP_CONF_DIR/tez-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/apps/tez-0.9.0.tar.gz</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
<property>
<name>tez.tez-ui.history-url.base</name>
<value>http://localhost:8080/tez-ui/</value>
</property>
</configuration>
EOF
1.5.append configurations to yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:8031</value>
</property>
1.6.append configuration to core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/hdfs/tmp</value>
</property>
<property>
<name>hadoop.http.filter.initializers</name>
<value>org.apache.hadoop.security.HttpCrossOriginFilterInitializer</value>
</property>
1.7.unpackage tez-dist/target/tez-0.9.0-minimal.tar.gz
1.8.append env to /etc/profile
export TEZ_CONF_DIR="location of tez-site.xml"
export TEZ_JARS="location of unpackaged tez-0.9.0-minimal.tar.gz"
export HADOOP_CLASSPATH=${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/*
1.9.start timelineserver
yarn-daemon.sh start timelineserver
1.10.configure tez ui, install tomcat, unpackage tez-ui/target/tez-ui-0.9.0.war into webapps, rename unpackaged directory to tez-ui
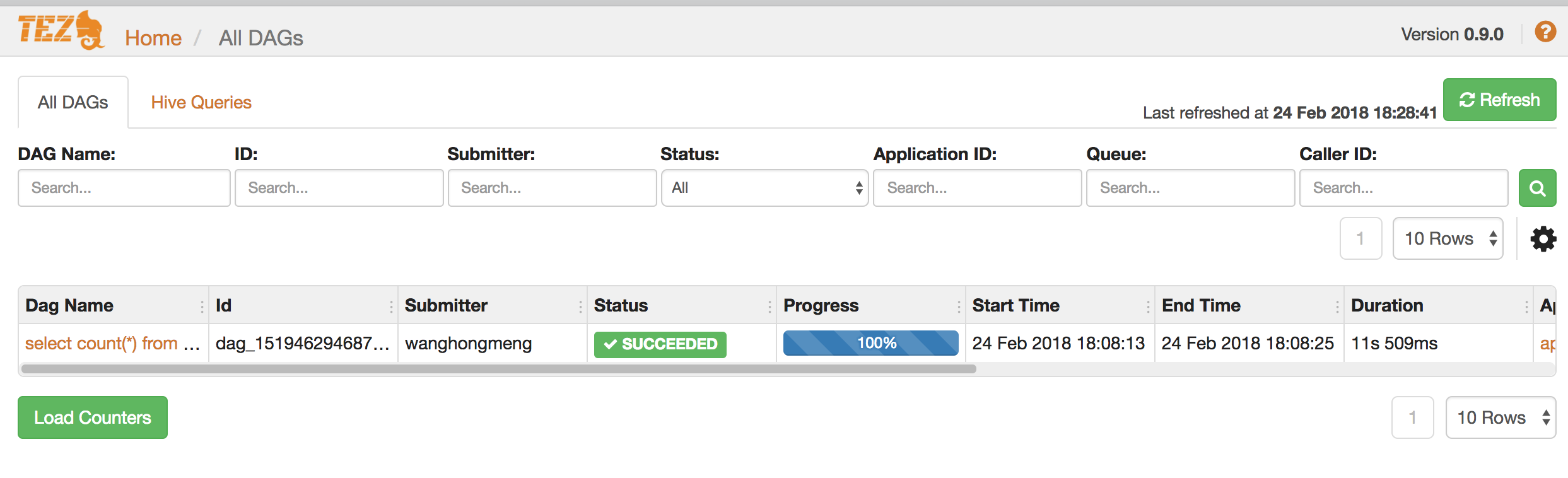
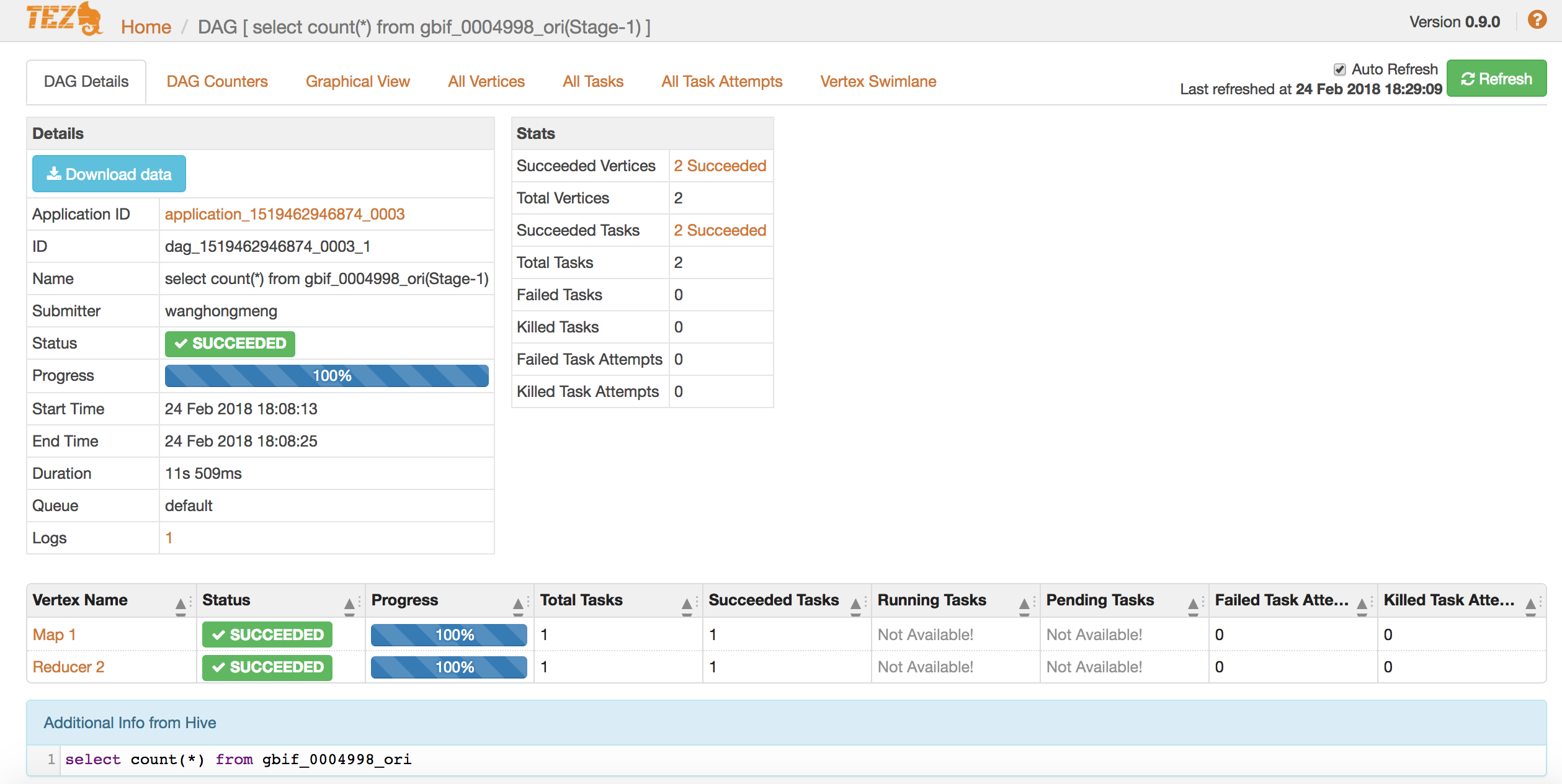
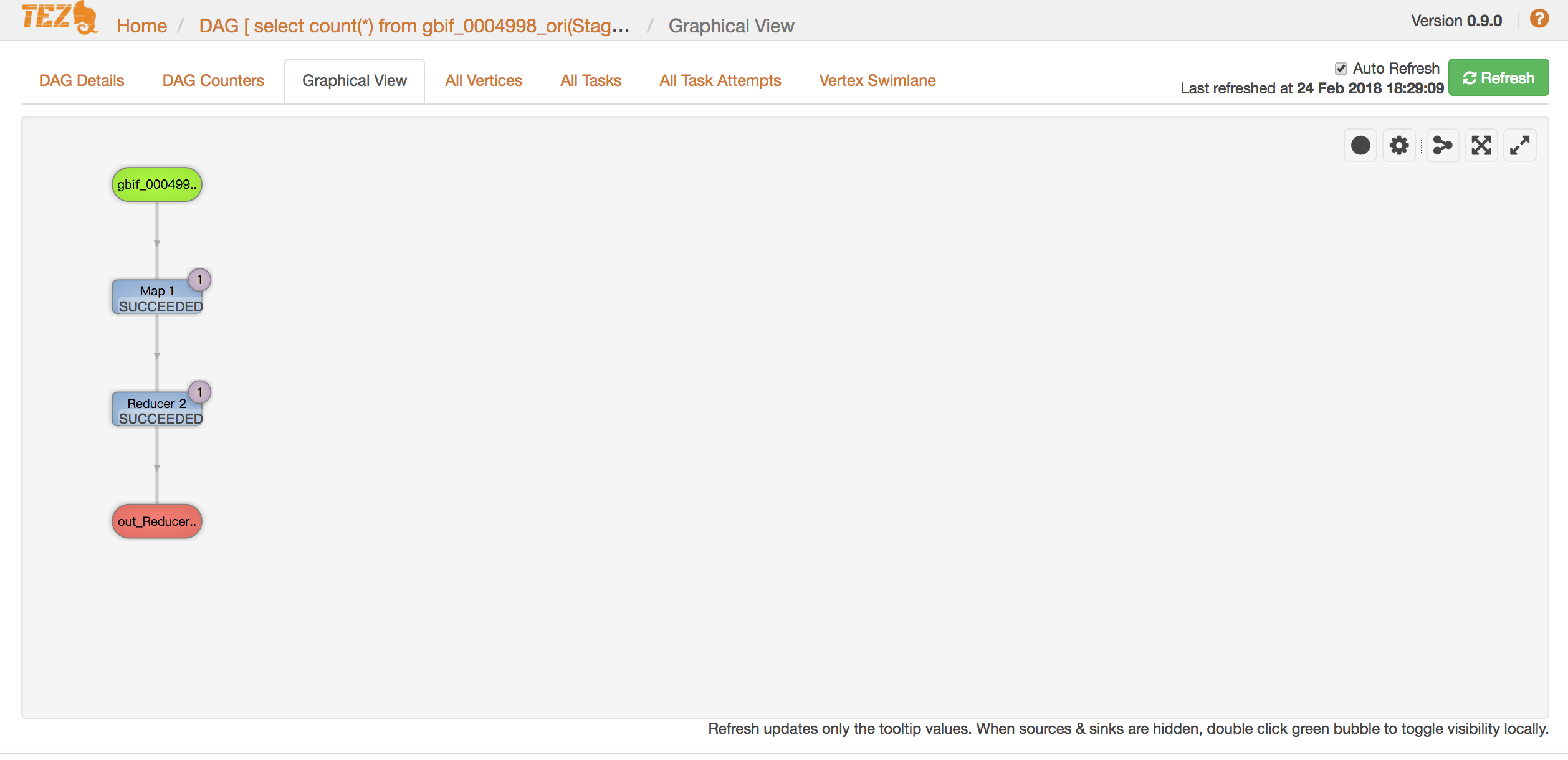
1.11.start tomcat, visit http://localhost:8080/tez-ui to test
2.test Tez
2.1.change job engine to Tez
hive> set hive.execution.engine=tez;
2.2.run job to test
hive> select count(*) from gbif_0004998;
Query ID = wanghongmeng_20180224180801_e5ddcf23-1e1a-4724-8156-1393807c2ac0
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1519462946874_0003)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 9.87 s
----------------------------------------------------------------------------------------------
OK
327316
Time taken: 23.876 seconds, Fetched: 1 row(s)
2.3.check result on tez ui




Reply